Chat, I'm not concerned about AI.
I'm concerned about me. I'm concerned about us.
The Benchmark: I knew better
In my last job I was asked to run and publish a benchmark as part of a product launch. The benchmark ran successfully and I thought the results looked okay. But I was new and I not super familiar with what I was testing. I also wanted to show my new employers that I was down with the AI thing. So I asked Claude to validate the results. I didn't write any skills or anything like that. I didn't even tell Claude what to check for. Even so, Claude told me that the benchmark ran successfully and that the measured performance was outstanding. Claude suggested that the benchmark was so outstanding that it should anchor the entire product launch. I wrote up a blog draft and shared it with the team.
A technical executive at the company took some issue with the writing and we worked through that. The edits were tonal. He didn't take any issue with the table that had all the numbers. We settled on a draft and the blog was published for the launch.
A few days later, another expert read the launch announcement and the numbers didn't look right to him. They looked too good.
Yeah, so that's when I finally grepped the benchmark log file for errors. Grepping a log file is something I've known how to do since the 90s. The practice has been engrained deep in my brain as step zero to validate the execution of anything involving a computer. I had skipped that part because I just assumed Claude did it. When I actually read the the log file I could discern what happened. There was a data load error. The benchmark queries ran a lot faster because the tables were smaller. Claude flagged that as amazing. Claude didn't flag the data load failure. Claude couldn't tell from the log how big the tables were supposed to be.

It's on me, I didn't specify what validation looks like. Claude was trying its best, and this was a hell of an oops. The benchmark needed to be rerun, the blog needed to be taken down and rewritten, the air felt taken out of the launch.
I wasn't fired and people seemed to understand. I would chalk this up to a "new job mistake" combined with "fast moving small company without clear process" and move on, but it has been sitting with me for a long time now.
I think it was an example of something else going on at a bigger scale. And not just with me. We have leapt headfirst into this new age without really understanding how to use these tools.
The Interview: We can tell. Can you?
I was in the job market in the last year. I did a lot of job interviews and I used chatbots a lot to study up, with mixed results. I walked through Google Cloud's excellent training modules on LLMs, and then asked Gemini and ChatGPT questions when I had them. I got what felt like decent clarification, and I started to feel like I had a decent ground level understanding of the technologies at work. I also had them pitch me some mock interview questions and gauge my answers. It was going great. It was going awesome. I felt prepared. Until one interviewer asked me about MCP. I had no idea what it was at the time and subsequently borked the interview. I went back and asked Gemini and ChatGPT both. Both made up some BS about what MCP was. "Ask Claude," the interviewer suggested. "MCP is from Anthropic." Live and learn.
For another interview, I decided I probably didn't need to cram too hard for a tech screen, since Google and AI are both things which we use every day now. I borked a moderate level SQL question, even though I have about 30 years of experience working with SQL. I genuinely didn't expect to have to answer that kind of question, since it was the kind of question we'd just ask Claude now. I gotta say, I was a little irked.
On the other end, a colleague told me a story about how difficult it has been to find a good fit for an open position. He told me that a big part of the problem is that candidates are regularly using AI during the interview without disclosure. Even though use of AI is increasingly expected in our day to day work, the impression is that people generally don't understand when using it helps or hinders their efforts. Are people generally, genuinely confused? Do they really not know if it is okay to pass your interview questions to an AI if you're passing your coding tasks to Claude code generating your code all day long? Or are they just doing their best to keep up in a fast, tough market?

And the meetings are different
I was in a cross functional marketing meeting where the topic of the meeting was strategy with respect to a competitor. After a natural moment of silence, someone spoke up and announced that they asked ChatGPT what our strategy should be. They shared their screen and we all read it. Next, the group simply agreed to do what ChatGPT said. That was the strategy. Meeting adjourned.

In a second meeting at another company, management set an expectation that software engineering now involves, primarily, code and doc review. There was a good amount of discussion about how even though much of our code is AI generated now, more of our time is spent reading, reviewing, and in validation.

Shipping the hallucinations
Some time back I was wasting time on Reddit (as one does) and I came across this beautiful moment:
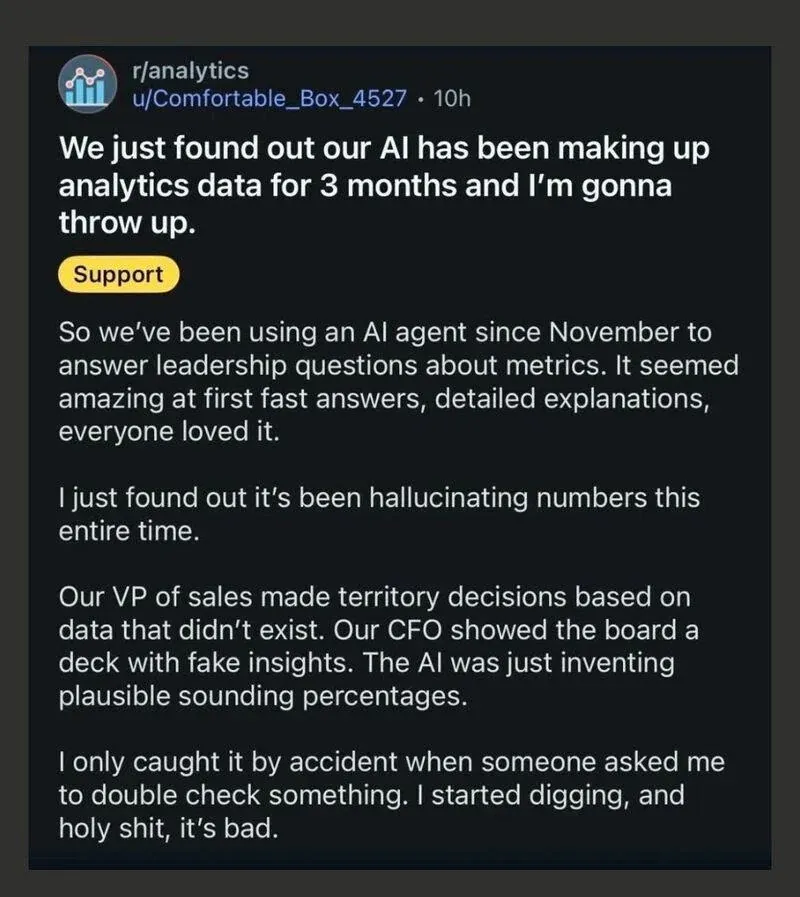
The post has since been removed, though it ranked highly on Reddit for a while. I can’t verify whether it’s true, and that’s kind of the point. It circulated widely regardless of its accuracy.
As I discussed in my last entry, I tried to use Gemini to come up to speed. I witnessed it make up non-existent features and double-down when questioned, even producing fake documentation links. I felt dumb for falling for it again but I wasn't the only one. Text produced by a coworker's conversation with Claude included a feature that exists in in another product but not ours. Once I noticed that, I found a set of derived internal docs all claiming the supported feature. Even though the coworker was clear that the output of his session was directional and not literal, I had to stop the organization from baking the hallucination into official guidance.
We know AI hallucinates. Why are we shipping the hallucinations?

There is definitely something bigger going on. I'm not talking about AI, AI hallucinations or AI producing incomplete work. I'm talking about a constellation of human mistakes made, repeatedly, in the presence of AI, by people who know better. I think these mistakes are caused by a set of common, reasonably well understood cognitive biases.
AI is amplifying existing human fallacies at scale and accelerating their propagation.
Fallacies at play here include but are not limited to:
- Comformity Bias / Social Pressure: "everyone is using AI so I need to" - people are using AI because they feel like they have to. I knew how to grep a file, but I wanted to show that I could use Claude too.
- The ELIZA Effect: "it looks right so it must be" - the tool generates something that seems true, but because we're presuming the tool is using a human thought process, we're accepting the result as authoritative. I thought I ran a good benchmark, Claude agreed, so I went with it.
- Automation Bias: "it said it's right, so I don't need to check" - once a process becomes automated, people implicitly trust the output of the automation. I didn't tell Claude how to validate a benchmark and I didn't validate it myself until it was too late.
- Diffusion of Responsibility: "I assumed they checked. They assumed I checked" - Responsibility is shared across people and systems, so verification is assumed rather than done and nothing actually gets checked.
- Goodhart's Law: "“it passed the metric, so it must be right” - a proxy like benchmarks or “AI validation” becomes the goal so we optimize for the signal instead of the underlying truth.
- Authority Bias: “they signed off, so it must be right” - we assume correctness because someone with status or perceived expertise approved it, rather than checking it ourselves.
- Fundamental Attribution Error: “the AI messed up” - we blame the tool for failures that are actually caused by human decisions, workflow design, or lack of verification.
I think very human faults like these are working together to produce compound failure modes in the human systems that are making use of AI at scale without adequate checks.
There is no doubt that the technology is disruptive. Prior to this new era, it felt like I would stare blankly at a screen for hours, if not days. Task initiation felt like moving a boulder. Once it got moving, there was momentum and productivity, but starting took a tremendous amount of effort. Now, the flow comes much easier. I can start with a prompt, an rough explanation of the task, even a feeling, and my AI companion sends us off to the races. I simply love that. I particularly love correcting en errant AI. Nothing is more motivating than pure indignation.
It’s pretty standard for organizations adopting AI to emphasize that individuals remain accountable for the work they produce, regardless of whether it’s AI-generated. Responsibility is clearly assigned, but verification becomes less structured the further you move from code. Engineers operate inside review and testing loops; adjacent functions might not, even though their output still reaches production in other forms: product specifications, documentation, marketing copy, and more. I’m concerned that as this scales across an economy, the divergence deepens until you reach a point where nothing is actually checked, even though everything appears to have been written by someone.
Popular media is full of conversation emphasizing the need to keep humans in the loop. I haven't heard any conversation about the importance of humans maintaining their judgment during this time of critical change.


