Developer-First Stream Processing with MongoDB

Building my first data pipelines with MongoDB Atlas Stream Processing and quantifying the experience
initialSync: my first stream processors
My initial work with MongoDB Atlas Stream Processing can be found in this repository.
In my prior work with MongoDB, I was accustomed to streaming data to MongoDB Atlas from Confluent using the fully managed MongoDB Atlas Sink Connector. So my first "no Flink" example of Atlas Stream Processing uses Terraform to spin up:
- A cluster in Confluent Cloud
- A datagen source connector generating stock trade data
- A MongoDB Atlas Kafka sink connector
- A MongoDB Atlas cluster
- A MongoDB Atlas stream processing workspace
- 4 MongoDB Atlas stream processors doing time window aggregations of the collection populated by the sink connector.
- Min / Max Trades
- Trades per ticker
- Unique tickers
- Pseudo-complex Event Processing matching a pattern within the window
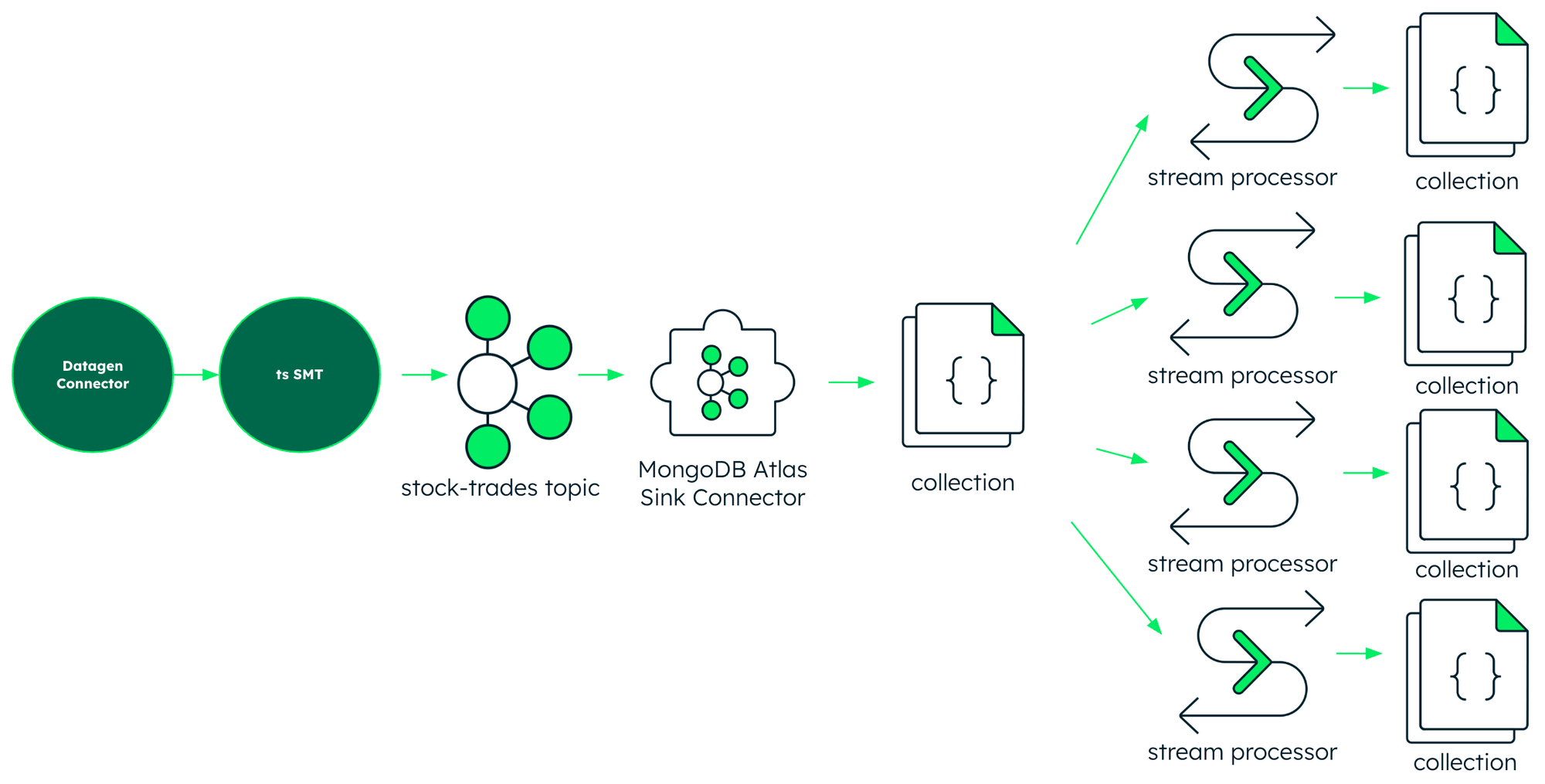
This is a good place to start if you're like me and coming at Atlas Stream Processing from the point of view of someone familiar with Confluent. It shows how, when MongoDB Atlas is a primary sink in your data infrastructure, doing stream processing there just makes sense and is a viable choice.
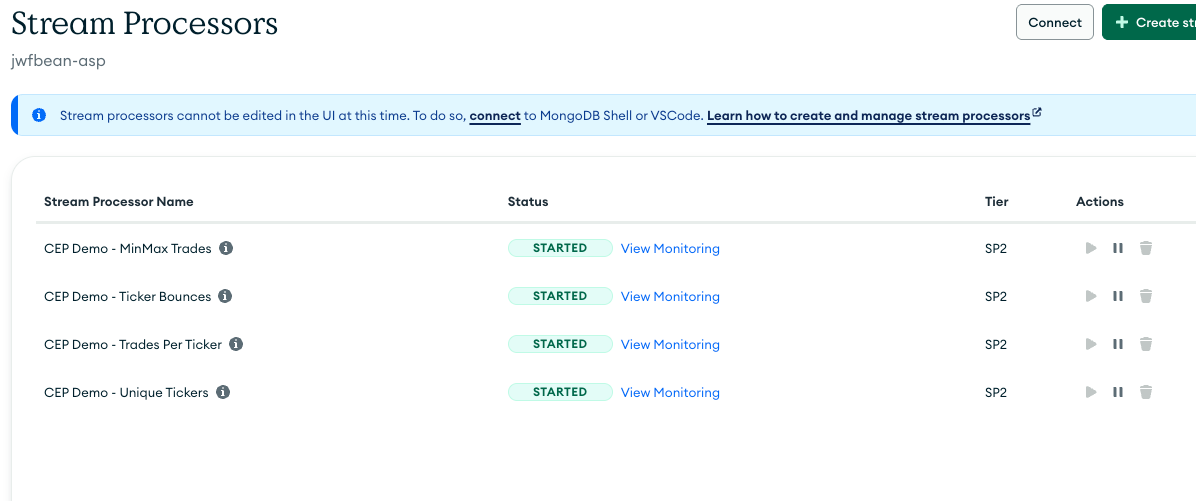
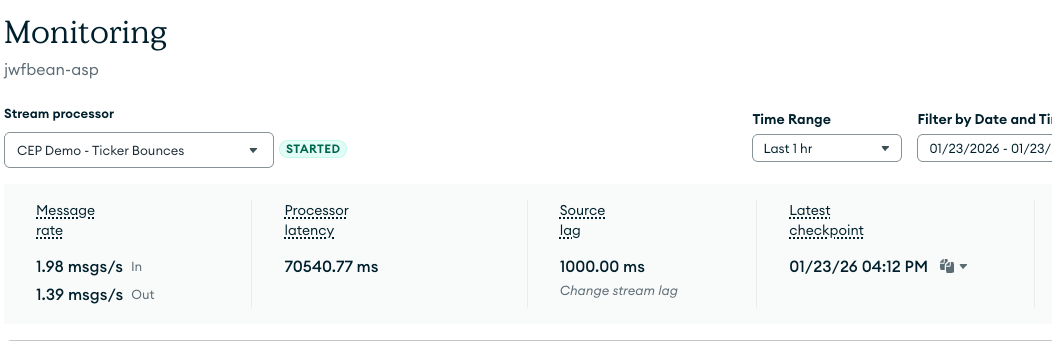
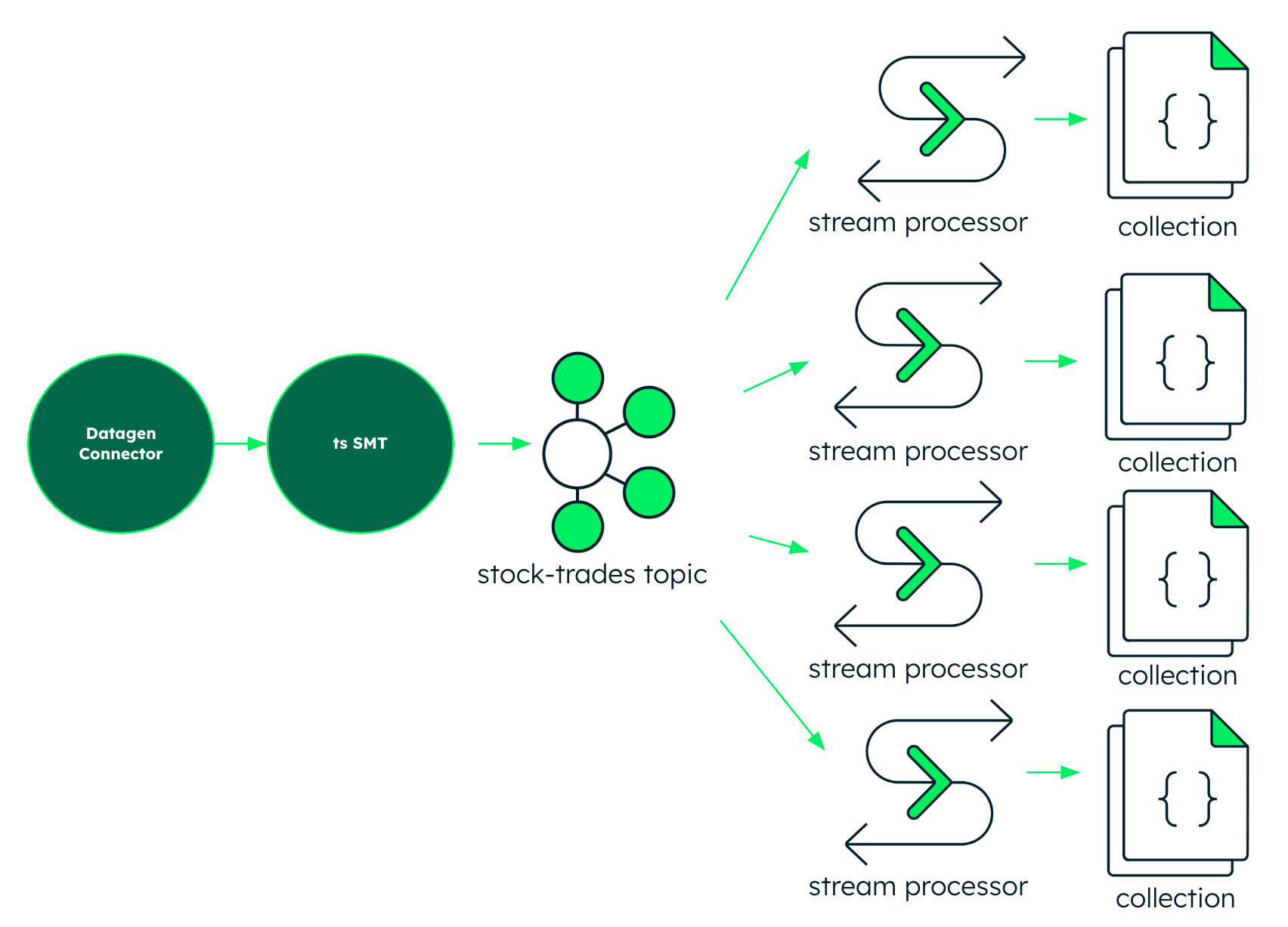
But Atlas Stream Processing is a direct Kafka consumer. My second "No Flink, No Sink" example switches the $source stage to read from a topic instead of a collection, eliminating the latency of a hop through a sink connector as well as the redundant overhead of Kafka Connect. The example uses Terraform to spin up:
- A cluster in Confluent Cloud
- A datagen source connector generating stock trade data
- A MongoDB Atlas cluster
- A MongoDB Atlas stream processing workspace
- 4 MongoDB Atlas stream processors doing time window aggregations of the collection populated by the sink connector.
- Min / Max Trades
- Trades per ticker
- Unique tickers
- Pseudo-complex Event Processing matching a pattern within the window
For the third example, I switched gears to time-series stream processing. I used the schema and data sets in RTABench to demonstrate how, when event data is processed in stream, you can pre-materialize a denormalized time-series collection which is optimized on the fly for aggregate analysis. There's still some work to do on this one. The Terraform plan will spin up the infrastructure for you but the developer still has to load the data and run the kick off the stream processor manually.
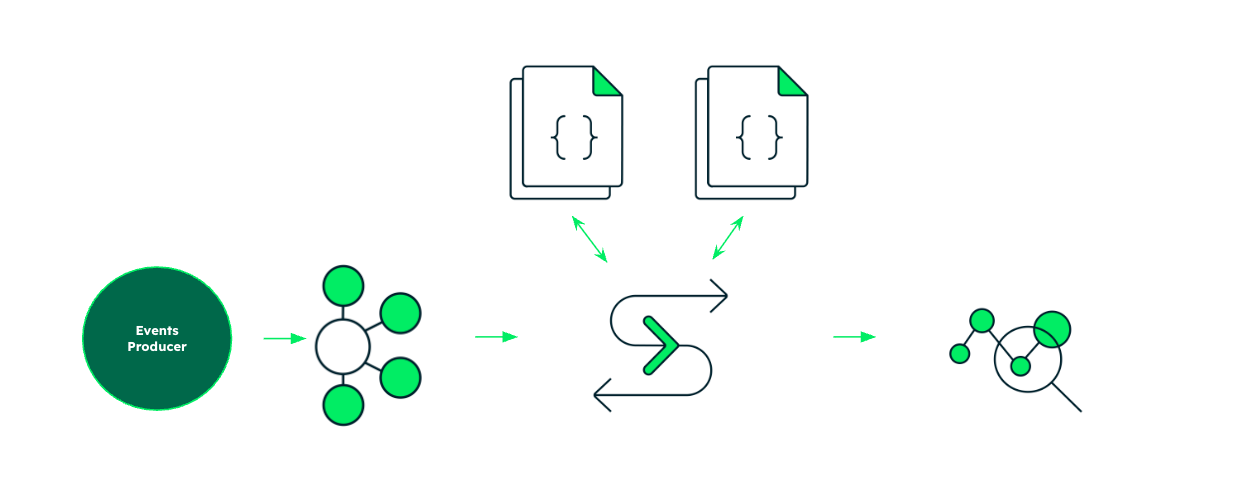
oplog: the story of my process
One of my favorite things to demo in Apache Flink is Complex Event Processing, or CEP. From StateMachineExample to the bounce-detector that uses MATCH_RECOGNIZE, I find demoing CEP to be a satisfying example of robust stream processing.
This isn't because CEP is a particularly typical example of stream processing in production. While tasks such as pattern recognition, anomaly detection, state machine execution and so on are definitely the stuff of production stream processing, most jobs that do this stuff don't use CEP semantics. Even so, it demos really well and serves as a concise, dense example of code doing something considerably more sophisticated than a simple count or a time window aggregation.
So when I was first learning MongoDB Atlas Stream Processing, I used Complex Event Processing as my north star. I wanted to see how easy it was to go from a basic understanding of MongoDB to using Atlas to do something somewhat sophisticated, when you have access to modern AI-backed development tools which happen to be really good at converting between different frames of reference, such as relational vs document models or batch vs streaming.
In the spirit of crawling before you could run, I built three other stream processors of increasing complexity first. I wanted to make sure I could deploy simple, table stakes stream processors. Establish a window. Find the min and max. Count the events in a time window. Count the events per unique type, and so on.

With VSCode and Google Gemini at my fingertips, I tried multiple approaches to Complex Event Processing, two of which actually executed. While Atlas Stream Processing doesn't have embedded state, it has $function which lets you specify any kind of logic you want using Javascript.
I thought this was silly at first, and I felt weird using it:

What I liked about it though was that it was relatively simple to understand. It also ran and produced verifiably correct output. I don't think it'd be too hard to correct for the case where the bounce spans a window boundary.
Atlas Stream Processing also has session window support. A bounce pattern could be detected by finding the minimum of a per-ticker session with a defined idle time between sessions. Google Gemini gave me something that ran, but I didn't understand it well enough to validate the results so I could confidently include it here.
So I was able to deploy a running approximation of the FlinkSQL bounce-detection CEP example on flink.apache.org as my fourth stream processor along with the others within half a day. This was super impressive. I couldn't even do that my first time running FlinkSQL on Confluent Cloud's fully managed service without seeking help from a project committer so I could understand how managed Flink was handling time semantics (to be fair, it was new and undocumented at the time). The biggest time sink for me with Atlas Stream Processing was understanding that the engine was doing this applying event timestamps automatically as expected.

rollback: intellectual honesty about the friction
As an aside, this year I've found myself adopting a particular corporate value as a personal value for the first time in my career. That value is intellectual honesty. It's not that I was ever intentionally dishonest. I think everyone in the industry means well and tries to be intellectually honest. But when you don't explicitly keep it in mind as a value, you can inadvertently confuse your audience. In that spirit, it wouldn't be intellectually honest if I didn't share some of the challenges I ran into in this exercise. As a theme, these issues were mostly due to my unfamiliarity with MongoDB.
Familiarity
While I was quite familiar with the benefits of schema-flexible distributed systems, I spent the last few decades thinking in terms of Java, relational databases, and event streaming. It took me a little while to appreciate how naturally MongoDB supports rapid iteration. I had to learn the tools: the MongoDB Atlas UI, mongosh and MongoDB's VSCode plugin. I also had to get used to the tension between proper json formatting and the flexibilities afforded by Javscript, particularly around quoted literals. Lastly, I found a stream processing pipeline defined with squiggles and quotes and dollar signs disorienting at first.
Lyin' AI'in
Because I was less familiar with MongoDB and associated development cadence, I got help from AI, particularly Google Gemini and the chat interface to VSCode. I was really surprised at how little these systems knew about Atlas Stream Processing and how consistently they brazenly hallucinated about it. Google Gemini insisted that Atlas Stream Processing had a $matchRegcognize function:

When questioned, the thing doubled down and even produced fake links to documentation that doesn't exist and never existed.
When AI is right, it's a super helpful productivity tool. When it's wrong, it's extremely, very brazenly wrong.
When AI had the context provided by the VSCode interface, the brazen hallucinations seemed to greatly diminish. And I'm still not quite clear on how to measure the level of consistency and quality of AI query responses. But what is clear is that we need more context out there in the form of documentation and evagelism. This experience led me to help the team evangelize Atlas Stream Processing more, both to machines (maybe via skills) and the people (maybe via this blog).
election: the bold claim: Atlas Stream Processing is a serious contender for any stream processing workload.
As a result of this experience I drew a comparison between Atlas Stream Processing and other stream processors such as self-managed Apache Flink, ksql, Spark Streaming, the Confluent Data Streaming Platform (consisting of fully managed Flink, Kafka, Kafka Connect all provided as part of Confluent Cloud), and Redpanda Connect / Benthos.
I considered the technologies along various dimensions such as developer experience, computational sophistication, ecosystem / community, operational maturity, and overall economics.
I found MongoDB Atlas Stream Processing performed very well in developer experience since I was able to quickly deploy functional stream processors, outperforming Flink based solutions in terms of time to productivity. Developer experience as measured in time-to-productivity was really ksql's only strength and it is decently rivaled by Atlas Stream Processing. Also, MongoDB's flexible document model enables developer agility like nothing else and it makes perfect sense for the framework to carry this trait over to streaming and stream processing.

Because it is built on mongod and inherits a lot of goodness from its adjacency to MongoDB Atlas, it ranks very well in operational maturity. I trust that the stream processors I developed, even the funky one that uses $function, will scale to meet workload demands when deployed in the higher tiers. Because sizing and tier selection is simple, the price-predictability of Atlas Stream Processing ranks it very well in overall economics.
The upshot is that Atlas Stream Processing is a very strong contender when selecting a stream processor, especially when MongoDB Atlas is already in heavy use in your organization.

changeStream: thanks for reading. what's next?
I'd like to hear from you. This blog is new and it's a hobby. I aspire to make it a regular thing. I hope to cover technology topics such as specific use cases around streaming and stream processing. But I'd also like to write about new trends and the various considerations in technology, data infrastructure and AI. I've also been in the industry for a while and have insights to offer around career choices, compensation / equity packages, and professional practices. I also hope to explore the intersection between corporate and personal values in regards to ideas like intellectual honesty. What would you like to read more of?
